
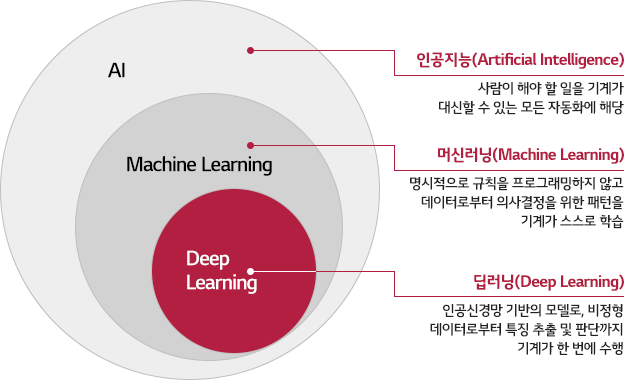
인공지능, 머신러닝, 딥러닝
인공지능 학습방법

- 지도학습
- 모든 입력패턴에 대해 정확한 답을 가지고 신경망을 학습하는 방법.
- 입력이 주어짐에 따라 원하는 출력값이 활성화되도록 가중치를 조절
- 각 입력자료에 대해 원하는 목표 출력값을 대응시켜 학습자료 구성
- 비지도학습
- 목표값 없이 학습 데이터만 입력, 스스로 연결 가중치들을 학습
- 주어진 입력패턴 자체를 기억시키거나, 유사한 패턴을 군집화 시키는데 사용
- 입력에 대한 정확한 답을 알 필요가 없으며, 입력 데이터에 내재된 구조나 그 사이의 관계를 파악하여 패턴들을 분류
- 강화학습
- 데이터의 상태(State)을 인식하고 이에 반응한 행위(Action)에 대하여 환경으로부터 받는 포상(Reward)을 학습하여 행위에 대한 포상을 최적화하는 정책(Model)을 찾는 기계학습
- 반복적인 결정 및 착오와 경험에 기반하여 상태의 최적의 행동을 조금씩 학습하는 알고리즘
GPU, CUDA
- GPU(Graphics Processing Unit)
- 원래는 게임 그래픽 처리를 위한 전용 칩셋이었으나 이후 병렬연산에 최적화되어 있다는 점을 이용해 다양한 과학 계산에 활용됨. 특히 딥러닝과 블록체인에 필요한 가장 중요한 핵심 하드웨어로 자리 잡음.
- CUDA(Compute Unified Device Architecture)
- 마이크로소프트가 게임 개발을 위해 DirectX 라는 API 를 제공하는 것처럼 GPU 로 병렬연산을 할 수 있도록 엔비디아가 직접 제공한 기술.
딥러닝 라이브러리
- 텐서플로(TensorFlow) : 구글 내부에서 사용하던 딥러닝 라이브러리를 2015년 가을에 오픈소스로 공개한 프로그램으로, 현재 딥러닝 프로그램 점유율 1위를 차지
- 파이토치(PyTorch) : 페이스북에서 오픈소스로 공개한 딥러닝 프로그램으로, 텐서플로에 이어 두 번째로 점유율이 높음, 특히 간단하고 직관적인 방식으로 복잡한 모델도 이해하기가 쉬워서 연구자들이 논문을 쓸 때 가장 많이 활용
용어 정리
- Accuracy(정확도)
- 전체 데이터에 대한 예측 오류의 수. 쉽게 말해, 전체 데이터 중에서 몇 개를 맞췄는가. 100개 중 97개를 맞췄다면 accuracy는 97%.
- 손실(Loss)
- 실제 정답과 모델이 예측 한 값 사이의 차이(거리 또는 오차) 즉, 손실이 클수록 데이터에 대한 오류도 커짐. 쉽게 말해, 틀리게 예측한 경우 얼마나 오류를 범했는가로 볼 수 있음. 따라서 2개의 모델이 100개 중 97개를 똑같이 맞춰도 둘의 오차는 다를 수 있음.
- 알고리즘이 iterative 하다는 것
- 결과를 내기 위해서 여러 번의 최적화 과정을 거쳐야 되는 알고리즘
- 다루어야 할 데이터가 너무 많고, 메모리가 부족하기 때문에 한 번의 계산으로 최적화된 값을 찾는 것은 어려움. 따라서, 머신 러닝에서 최적화(optimization)를 할 때는 일반적으로 여러 번 학습 과정을 거침. 또한, 한 번의 학습 과정 역시 사용하는 데이터를 나누는 방식으로 세분화시킴
- epoch
- 전체 데이터 셋에 대해 한 번의 학습 과정이 완료된 상태
- epochs = 40 → 전체 데이터를 40번 사용해서 학습을 거치는 것
- iteration
- 한 번의 epoch 에서 데이터를 몇 번 나누어서 주는가
- batch size
- 각 iteration 마다 주는 데이터 크기

'ETC' 카테고리의 다른 글
| 그라파나와 프로메테우스 (0) | 2023.06.18 |
|---|---|
| CI/CD란 ? (0) | 2023.06.18 |
| EDA(Event Driven Architecture) (0) | 2023.06.14 |
| RabbitMQ와 Kafka (0) | 2023.06.13 |
| Tokenizer란? (0) | 2023.06.12 |