ETC
쿠버네티스(k8s)의 간단한 동작 방식 및 etcd - 쿠버네티스 시리즈(2)
D_Helloper
2023. 7. 4. 18:54
쿠버네티스의 동작 방식
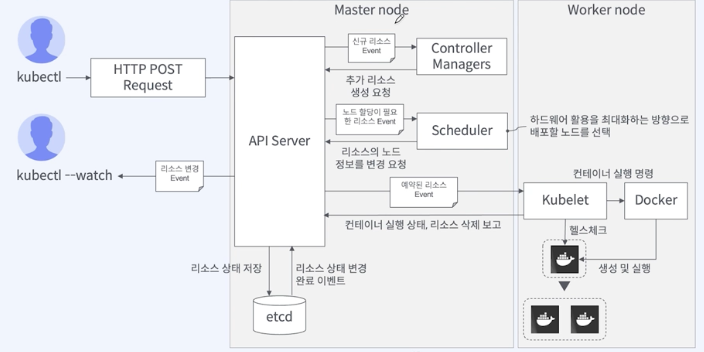
- 사용자는 kubectl을 통해 쿠버네티스 클러스터와 통신
- 클러스터 내의 Master는 쿠버네티스의 설정 환경을 저장하고, 전체 클러스터 관리
- 각 Node들에서는 쿠버네티스 위에서 동작하는 워크로드(pod)들이 실행
- 쿠버네티스는 기본적으로 내가 원하는 상태(Desired State)와 현재 상태(Current State)를 비교
- 만약 상태가 서로 다르다면, 현재 상태를 원하는 상태로 변경하는 기능 수행
- etcd에 api의 내용 저장
- api server에 선언형 api로 요청이 들어올 경우, 바로 동작을 실행하지 않고 etcd에 들어온 내용을 저장
- etcd를 감시하는 controller 동작
- controller는 etcd에 내가 담당하는 resource가 들어왔는지를 감시하다가, 해당 resource가 들어온 경우 스케줄러에게 동작을 요청
- 비즈니스 로직이 controller에 포함
- 스케줄러 동작
- 워커 노드의 kubelet과 통신
- kubelet 동작
- 노드에 pod을 생성
쿠버네티스가 etcd를 사용하는 방법
- 모든 객체(Pot,Deploy)는 매니페스트 파일로 저장
- 해당 매니페스트 파일을 etcd에 저장
- etcd에 저장된 매니페스트의 상태(Desired)와 동일하게 클러스터를 유지하려고 함
- 쿠버네티스는 API Server를 통해서만 etcd에 CRUD를 함(아래 장점을 얻을 수 있음)
- 낙관적 락
- 유효성 검사
- 매니페스트 파일에 접근하려고 할 때, 유요한 매니페스트 파일인지는 API Server가 검사해 줌
- 또한 여러 API Server가 동시에 매니페스트 파일을 업데이트 하려고 할 때, 버전으로 관리되는 낙관적 락을 통해서 Race Condition을 해결하도록 동작할 수 있음
쿠버네티스에서 리소스를 etcd에 저장하는 방법
- 배포된 리소스는 모드 etcd에 저장
- etcd의 /registry 아래에 key/value 형식으로 리소스 저장
- 아래 명령어로 /registry 폴더 아래에 저장된 모든 key/value 데이터들에 대해 key값만 불러올 수 있음
// etcd에 저장된 쿠버네티스 매니페스트의 key값 살펴보기
$ etcdctl get /registry --prefix --keys-only
...
/registry/endpointslices/kube-system/kube-dns-jsrnd
/registry/endpointslices/kube-system/metrics-server-dcmvn
/registry/endpointslices/longhorn-system/csi-attacher-x8vs8
/registry/endpointslices/longhorn-system/csi-provisioner-dj5nl
// key 값으로 조회하기
$ kubectl get --raw /api/v1/namespaces/default/pods/my-pod
// alias 추가해서 손쉽게 접근하기.
alias etcdctl='ETCDCTL_API=3 etcdctl \\
--endpoints=https://192.168.0.200:2379 \\
--cacert=/etc/kubernetes/pki/etcd/ca.crt \\
--cert=/etc/kubernetes/pki/etcd/server.crt \\
--key=/etc/kubernetes/pki/etcd/server.key'
// 출처 : <https://ojt90902.tistory.com/1509>
- etcd에 저장된 값은 프로토버프로 저장되기 때문에 바로 읽을 수 없음
- value의 값을 확인하려면 kubectl의 —raw 옵션을 이용해서 key로 검색하면 됨
etcd 인스턴스가 홀수로 배포되는 이유
- RAFT 알고리즘으로 etcd 클러스터의 컨센서스를 이룸
- etcd는 과반수가 동의하는 리더 선출
- Write는 리더를 통해서만, Read는 리더가 아닌 노드로도 처리 가능
- 리더에게 쓰기 요청이 오면, 리더는 각 구성원에게 합의 요청
- 합의는 ‘N/2+1’의 노드가 응답하는 경우에 이루어 짐
- 합의가 이루어지면 리더는 쓰기 결과 반환
3개, 4개의 노드로 구성된 클러스터가 있을 때, 각 클러스트는 몇 개의 노드까지 실패할 수 있을까?
- 3개 클러스터 : 2개의 노드 합의가 필요함. 즉, 1개까지 실패 가능.
- 4개 클러스터 : 3개의 노드 합의가 필요함. 즉, 1개까지 실패 가능.
- 짝수 클러스터는 내결함성 관점에서는 홀수 클러스터에 비해서 전혀 이점이 없음
- 오히려 1개 더 많은 노드에도 데이터를 복사해야 하기 때문에 네트워크 비용이 짝수 클러스터가 더 많이 나옴
- 그래서 홀수로 배포함